
- CEO NVIDIA sẽ công bố những bước tiến mới của công nghệ AI tại GTC 2025
- NVIDIA GTC 2024: TSMC và Synopsys mang nền tảng NVIDIA Computational Lithography vào sản xuất chip bán dẫn
- ASUS giới thiệu các giải pháp trung tâm dữ liệu MGX tại sự kiện GTC 2024
- CEO NVIDIA sẽ tiết lộ những đột phá mới nhất trong Điện toán tăng tốc, AI tạo sinh và Robot học tại hội nghị GTC 2024
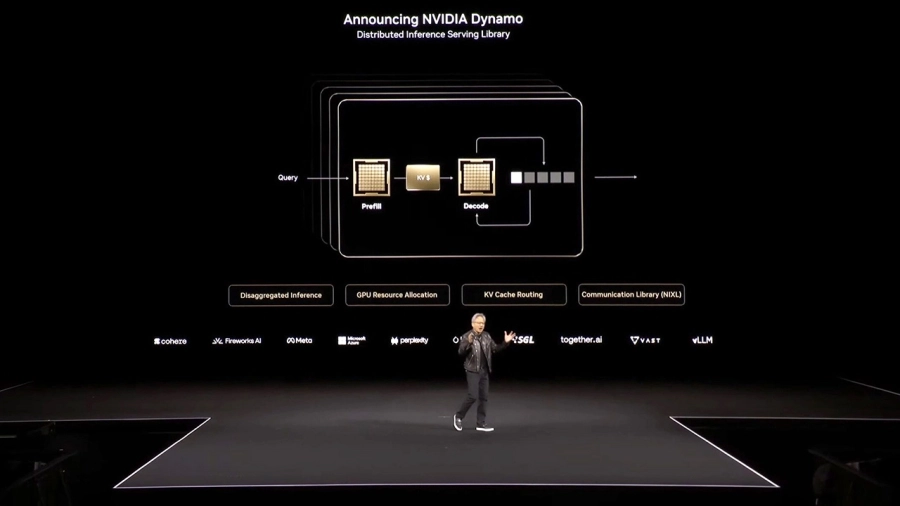
Tại hội nghị thường niên GTC 2025 đang được diễn ra ở Mỹ, NVIDIA đã chính thức công bố NVIDIA Dynamo, một phần mềm suy luận nguồn mở giúp tăng tốc và mở rộng quy mô các mô hình AI trong các “nhà máy AI” với chi phí thấp nhất và hiệu quả cao nhất.
Việc tối ưu hóa quản lý suy luận AI thông qua mô hình mã nguồn mở NVIDIA Dynamo trên các cụm GPU lớn là yếu tố then chốt để đảm bảo các hệ thống này vận hành hiệu quả, tối đa hóa doanh thu từ việc tạo token.
 |
Tăng tốc suy luận AI
Trong bối cảnh suy luận AI trở thành xu hướng chủ đạo, mỗi mô hình AI có thể tạo ra hàng chục nghìn token với mỗi câu lệnh. Điều này đặt ra yêu cầu phải không ngừng cải thiện hiệu suất suy luận đồng thời giảm thiểu chi phí để thúc đẩy tăng trưởng và mở rộng cơ hội doanh thu cho các nhà cung cấp dịch vụ AI.
NVIDIA Dynamo, phiên bản kế nhiệm của NVIDIA Triton Inference Server™, được thiết kế để tối đa hóa hiệu suất và lợi nhuận từ suy luận AI. Phần mềm này điều phối và tăng tốc quy trình suy luận trên hàng nghìn GPU, đồng thời sử dụng khả năng “phục vụ phân tách” để tối ưu hóa từng giai đoạn xử lý của các mô hình ngôn ngữ lớn (LLM). Điều này giúp đảm bảo hiệu suất cao nhất và tận dụng tối đa tài nguyên GPU.
Jensen Huang, CEO của NVIDIA, nhận định: “Các ngành công nghiệp đang ngày càng đào tạo các mô hình AI để suy nghĩ và học hỏi theo nhiều cách khác nhau. Để xây dựng một tương lai AI suy luận hiệu quả, NVIDIA Dynamo giúp mở rộng triển khai các mô hình này, nâng cao hiệu suất và tiết kiệm chi phí.”
Hiệu suất vượt trội
Dynamo giúp các “nhà máy AI” phục vụ mô hình Llama trên nền tảng NVIDIA Hopper™ tăng gấp đôi hiệu suất chỉ với cùng số lượng GPU. Khi chạy mô hình DeepSeek-R1 trên cụm GB200 NVL72, phần mềm này giúp tăng số lượng token được tạo ra hơn 30 lần trên mỗi GPU.
Để đạt được điều này, NVIDIA Dynamo tích hợp các tính năng nâng cao như:
- Điều chỉnh linh hoạt GPU: Thêm, xóa và phân bổ lại GPU theo nhu cầu.
- Định tuyến thông minh: Xác định chính xác GPU nào có thể xử lý yêu cầu với chi phí thấp nhất.
- Tối ưu hóa bộ nhớ: Chuyển dữ liệu suy luận sang bộ nhớ có giá rẻ hơn và truy xuất nhanh khi cần.
Mở rộng quy mô suy luận
NVIDIA Dynamo hỗ trợ các nền tảng AI như PyTorch, SGLang, NVIDIA TensorRT™-LLM và vLLM, giúp doanh nghiệp và nhà nghiên cứu dễ dàng triển khai mô hình AI trên các hệ thống suy luận phân tách. Phần mềm này sẽ được tích hợp vào AWS, Cohere, CoreWeave, Dell, Google Cloud, Meta, Microsoft Azure, và nhiều nền tảng khác.
Denis Yarats, CTO của Perplexity AI, chia sẻ: “Chúng tôi mong muốn tận dụng NVIDIA Dynamo để nâng cao hiệu suất và quy mô phục vụ suy luận AI, đáp ứng nhu cầu ngày càng cao của người dùng.”
Các công nghệ lõi của NVIDIA Dynamo
NVIDIA Dynamo bao gồm bốn cải tiến chính giúp giảm chi phí và cải thiện trải nghiệm người dùng:
- GPU Planner: Tự động điều chỉnh số lượng GPU phù hợp với khối lượng công việc.
- Smart Router: Định tuyến yêu cầu suy luận hiệu quả để giảm thiểu tính toán dư thừa.
- Thư viện giao tiếp độ trễ thấp: Tối ưu hóa truyền dữ liệu giữa các GPU.
- Memory Manager: Quản lý bộ nhớ thông minh, tải và lưu trữ dữ liệu với chi phí tối ưu.
NVIDIA Dynamo sẽ có sẵn trong các vi dịch vụ NVIDIA NIM và được hỗ trợ trong bản phát hành tương lai của nền tảng NVIDIA AI Enterprise. Với khả năng mã nguồn mở và mô-đun linh hoạt, Dynamo hứa hẹn giúp các doanh nghiệp tối ưu hóa chi phí và hiệu suất trong kỷ nguyên AI suy luận.
Tùng Nguyễn





{kind=link}